Announcing the release of LogCabin 1.1! This is the second stable release of the LogCabin coordination service, which includes a C++ implementation of the Raft consensus algorithm.
![]()
LogCabin has gotten a bunch of improvements and bug fixes in the three months since the release of LogCabin 1.0. The release notes list out all the details for v1.1: 4 high severity bug fixes, 6 low severity bug fixes, 6 internal improvements, 6 backwards-compatible changes, and 7 changes to unstable APIs.
A few of the more interesting changes are highlighted below, but all users are encouraged to upgrade so that they have the latest bug fixes.
logcabinctl
LogCabin was developed with clusters of servers in mind and where a single leader handles all client requests. The client library is structured so that most RPCs go through a LeaderRPC class to invoke operations on the cluster leader. The leader-based cluster RPCs were so pervasive that there was no way to ask a particular server to do something.
One of the more exciting changes in v1.1 is logcabinctl, a program to query
and modify the internal state of individual servers. I've found this to be very
useful for administrative and debugging purposes. For example, it lets you
change the debug log verbosity for a single server at runtime without shutting
it down, or ask a server to take a snapshot, or ask a server not to take
automated snapshots. We use that last feature at
Scale Computing to stop servers from
snapshotting after system-wide test failures, which improves our odds of
finding meaningful Raft log entries with the history of commands when we go to
triage the failure.
Performance improvements
I've been pointing out any performance-related changes in this series of blog posts, and there's a few of them in v1.1:
SegmentedStoragenow batches multiple entries to disk with a singlefdatasync()call. It was designed with this in mind, but an oversight allowed this optimization to be removed during cleanup (#165).- AppendEntries is now much more efficient in how it packs large batches of entries into requests (#161).
- Leaders will now cap the next index they'll send to a follower to be no more than one entry past the end of the follower's log. This helps speed up catching up new servers or servers that have fallen far behind (fcbacbb).
LogCabin talk
I gave a talk at Scale a couple days ago on how to use and operate LogCabin, along with how it works internally. Those slides are online for anyone interested.
To give you a taste, here's a diagram from the talk that maps out LogCabin's code layout. Further slides explain a little bit about what's in each directory.
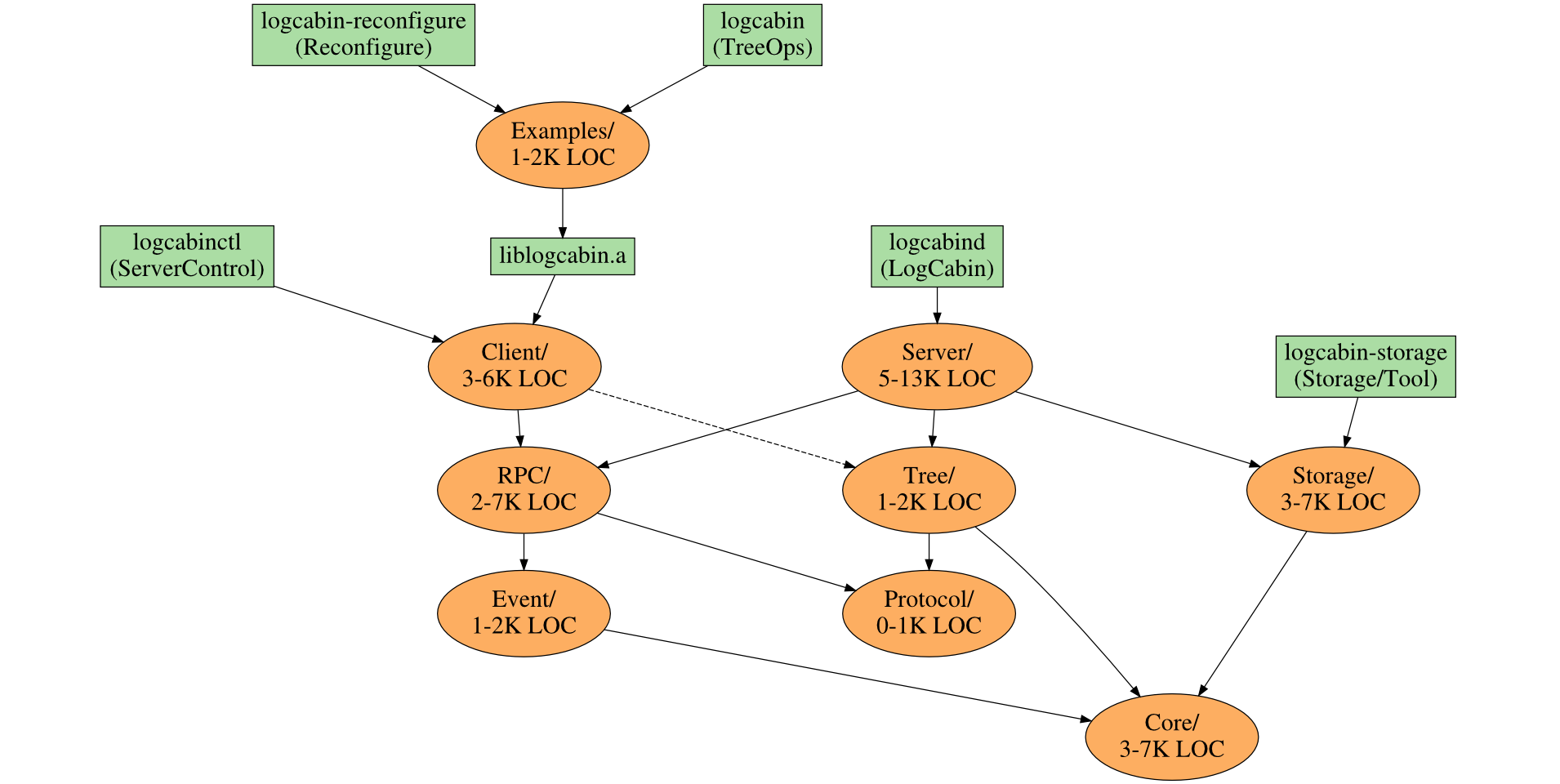
LogCabin in RAMCloud
Update: I've added support for LogCabin v1.1 in the RAMCloud storage system, where it can now be used for metadata storage and leader (coordinator) election. RAMCloud keeps all data in DRAM and offers 5 to 10 microsecond remote access times. It has a modular interface called ExternalStorage for its external coordination needs; this is implemented by ZooStorage for ZooKeeper and is now joined by LogCabinStorage for LogCabin.
Next for LogCabin
Scale Computing is testing their next release, which will include LogCabin v1.1, now, and they plan on shipping it to customer clusters soon. Today is my last day as a contractor for Scale, as I'm starting a full-time job elsewhere tomorrow (more on that in a future post). At least for now, I'll be taking a less active role in maintaining LogCabin: I'll be more of an integrator than a maintainer, answering questions and reviewing patches as they come up. Scale plans to continue using LogCabin and will take a more active role in maintaining it and building out new features as needed.
I'll take this opportunity to mention that Scale is looking for several more engineers, and they've recently closed an $18 million round of funding. Feel free to contact me directly if you'd like to chat about what it's like at Scale, and I can put you in touch with the right people there.
I'd like to thank Scale for supporting all of the work on LogCabin that we've done in the past 9 months. It's come a long way, and that wouldn't have been possible without Scale's commitment, their willingness to jump in and track down bugs, and their real-world use case driving new features. Those guys rock, and I hope we can keep collaborating on making LogCabin even better going forward.